
نرمافزار استاتا Stata یکی از قدرتمندترین و محبوبترین ابزارهای آماری در جهان است که بهویژه در رشتههای اقتصاد، علوم سیاسی، جامعهشناسی و علوم پزشکی کاربرد گستردهای دارد. این نرمافزار به دلیل توازن میان رابط کاربری گرافیکی و محیط کدنویسی، انتخابی ایدهآل برای پژوهشگران است. اگر در مسیر تحلیل آماری پایان نامه دکتری به Stata هستید، این ابزار به شما اجازه میدهد تا با دقت بسیار بالا، دادههای حجیم را مدیریت و تحلیل کنید.
برخلاف برخی نرمافزارهای مشابه، Stata ساختاری دستورمحور دارد که بازتولید (Reproducibility) نتایج را بسیار آسان میکند. در فرآیند تحلیل داده های رساله دکتری با استاتا، این ویژگی حیاتی است؛ زیرا داوران و اساتید راهنما ممکن است از شما بخواهند مراحل تحلیل را دقیقاً تکرار کنید. در ادامه، ۳۰ نکته کلیدی که در طول آموزش استاتا و اجرای پروژههای دکتری به آنها نیاز دارید، آورده شده است.
۳۰ نکته حیاتی در تحلیل آماری با Stata
۱. استفاده همیشگی از Do-file
فایلهای Do قلب تپنده تحلیل در استاتا هستند. به جای استفاده از منوهای گرافیکی، تمام دستورات خود را در یک Do-file بنویسید تا بتوانید با یک کلیک، تمام تحلیلها را از ابتدا تا انتها اجرا کنید.
این کار نهتنها از بروز خطاهای انسانی جلوگیری میکند، بلکه در زمان تحلیل داده های رساله دکتری با استاتا Stata به شما کمک میکند تا هر تغییری در دادههای خام را به سرعت در نتایج نهایی اعمال کنید.
۲. اهمیت برچسبگذاری (Labeling)
همیشه برای متغیرها و مقادیر آنها برچسب تعریف کنید. دستورات label variable و label values باعث میشوند که در خروجی جداول و نمودارها، به جای نامهای مخفف و گنگ، توضیحات کامل ظاهر شود.
در تحلیل آماری پایان نامه دکتری به Stata، شفافیت خروجیها بسیار مهم است. وقتی شش ماه بعد به فایل خود رجوع میکنید، برچسبها به شما یادآوری میکنند که عدد «۱» به معنای «گروه کنترل» بوده است یا «گروه آزمایش».
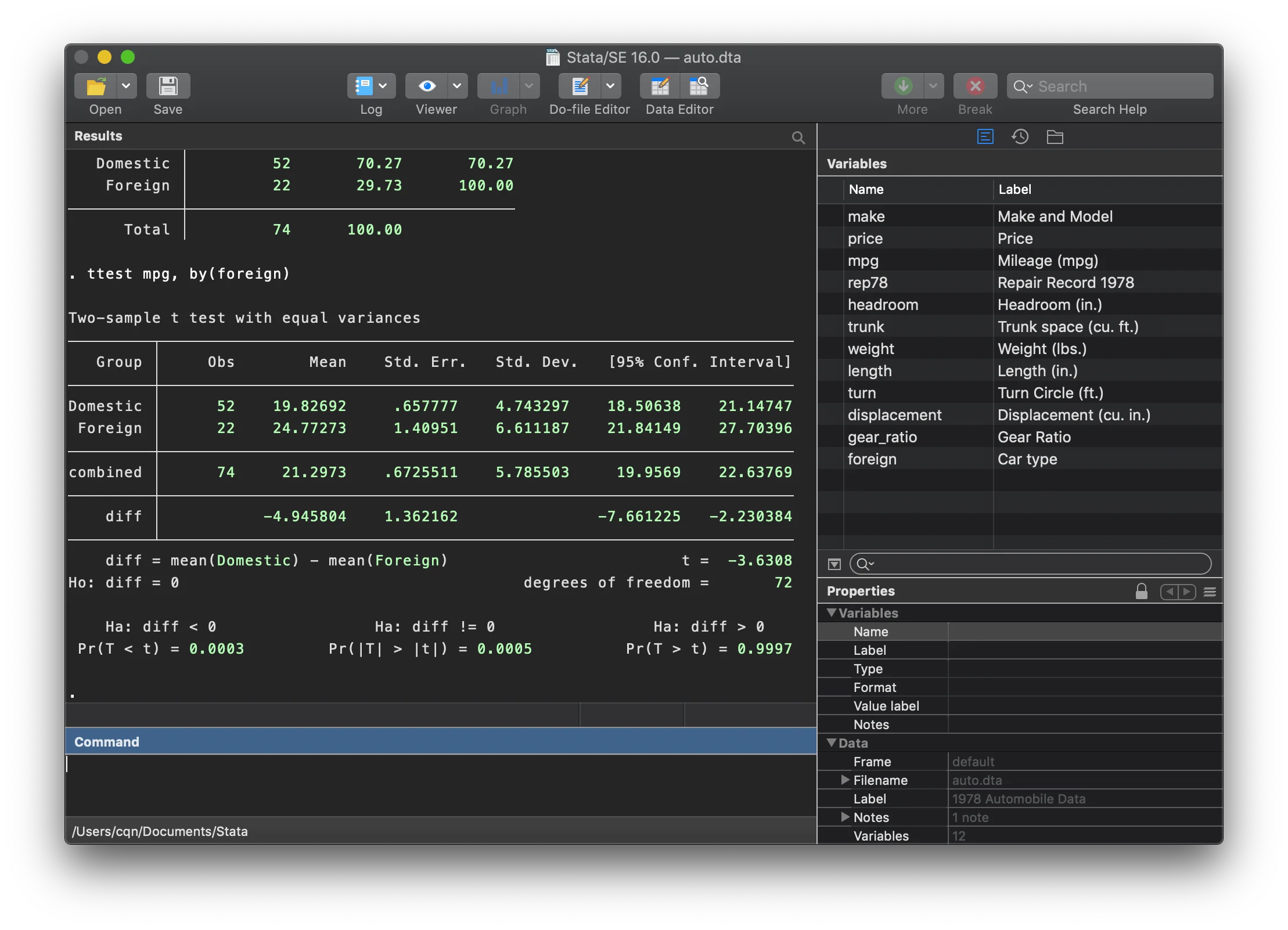
۳. مدیریت دادههای گمشده (Missing Values)
در استاتا، دادههای گمشده با نقطه (.) نمایش داده میشوند که از نظر ریاضی بزرگترین عدد محسوب میشوند. اگر به این نکته توجه نکنید، ممکن است در فیلتر کردن دادهها (مثلاً دستور keep if age > 60) دچار خطا شوید.
همیشه قبل از شروع تحلیل، وضعیت دادههای گمشده را بررسی کنید. استفاده از دستور misstable summarize دید خوبی از حجم دادههای از دست رفته در متغیرهای کلیدی رساله به شما میدهد.
۴. بررسی نوع متغیرها (Storage Types)
استاتا متغیرها را به صورت عددی (float, int, byte) یا رشتهای (string) ذخیره میکند. برای انجام تحلیلهای آماری، متغیرهای شما حتماً باید عددی باشند.
اگر دادهای را از اکسل وارد کردهاید و به صورت قرمز (رشتهای) نمایش داده میشود، حتماً از دستور destring یا encode برای تبدیل آن استفاده کنید تا در مدلهای رگرسیونی قابل استفاده باشند.
۵. استفاده از دستور summarize برای توصیف اولیه
اولین قدم در هر تحلیل داده های رساله دکتری با استاتا، بررسی آمارههای توصیفی است. دستور sum میانگین، انحراف معیار و مقادیر حداقل و حداکثر را به شما نشان میدهد.
این بررسی اولیه به شما کمک میکند تا دادههای پرت (Outliers) یا خطاهای ورود داده را شناسایی کنید. مثلاً اگر حداکثر سن در دادههای شما ۲۰۰ سال درج شده باشد، متوجه وجود خطا خواهید شد.
۶. رسم نمودارهای جعبهای (Boxplot) برای شناسایی پرتها
نمودارهای جعبهای بهترین ابزار برای شناسایی بصری دادههای پرت هستند. با دستور graph box میتوانید توزیع متغیرهای وابسته خود را در گروههای مختلف مقایسه کنید.
شناسایی و تصمیمگیری درباره دادههای پرت، بخش حساسی از آموزش استاتا است، زیرا این دادهها میتوانند نتایج رگرسیون شما را به شدت تحت تأثیر قرار داده و تورش ایجاد کنند.
۷. استفاده از دستور tabulate برای دادههای طبقهبندی شده
برای بررسی فراوانی متغیرهای اسمی و رتبهای، دستور tab ضروری است. این دستور توزیع درصدی را نشان میدهد و با اضافه کردن گزینه chi2 میتوانید آزمون خی-دو را نیز انجام دهید.
در جداول متقاطع، همیشه از گزینه cell یا row استفاده کنید تا سهم هر زیرگروه در کل نمونه مشخص شود. این موضوع در تحلیلهای جمعیتشناختی رساله بسیار پرکاربرد است.
۸. ترکیب فایلها با دستور merge
بسیاری از پژوهشگران دکتری نیاز دارند دادههای مختلف (مثلاً دادههای بانکی و دادههای کلان اقتصادی) را با هم ترکیب کنند. دستور merge 1:1 یا merge m:1 ابزار تخصصی این کار است.
دقت کنید که قبل از ترکیب، باید یک متغیر کلیدی مشترک (مانند کد ملی یا کد شرکت) در هر دو فایل وجود داشته باشد و دادهها بر اساس آن مرتب (sort) شده باشند.
۹. تغییر ساختار دادهها با reshape
گاهی دادههای شما به صورت Wide هستند (هر سال در یک ستون) اما برای مدلهای پانل نیاز دارید آنها را به صورت Long درآورید. دستور reshape long این کار را به سادگی انجام میدهد.
فهم دقیق نحوه عملکرد این دستور یکی از مراحل پیشرفته در آموزش استاتا است که برای محققانی که با دادههای سری زمانی-مقطعی کار میکنند، حیاتی است.
۱۰. تنظیم دادههای پانل با xtset
اگر دادههای شما ترکیبی از مقطع و زمان هستند، باید حتماً با دستور xtset id year ساختار پانل را به استاتا معرفی کنید.
پس از این دستور، استاتا متوجه میشود که مشاهدات شما مستقل نیستند و امکان استفاده از مدلهای اثرات ثابت (Fixed Effects) و اثرات تصادفی (Random Effects) فراهم میشود.
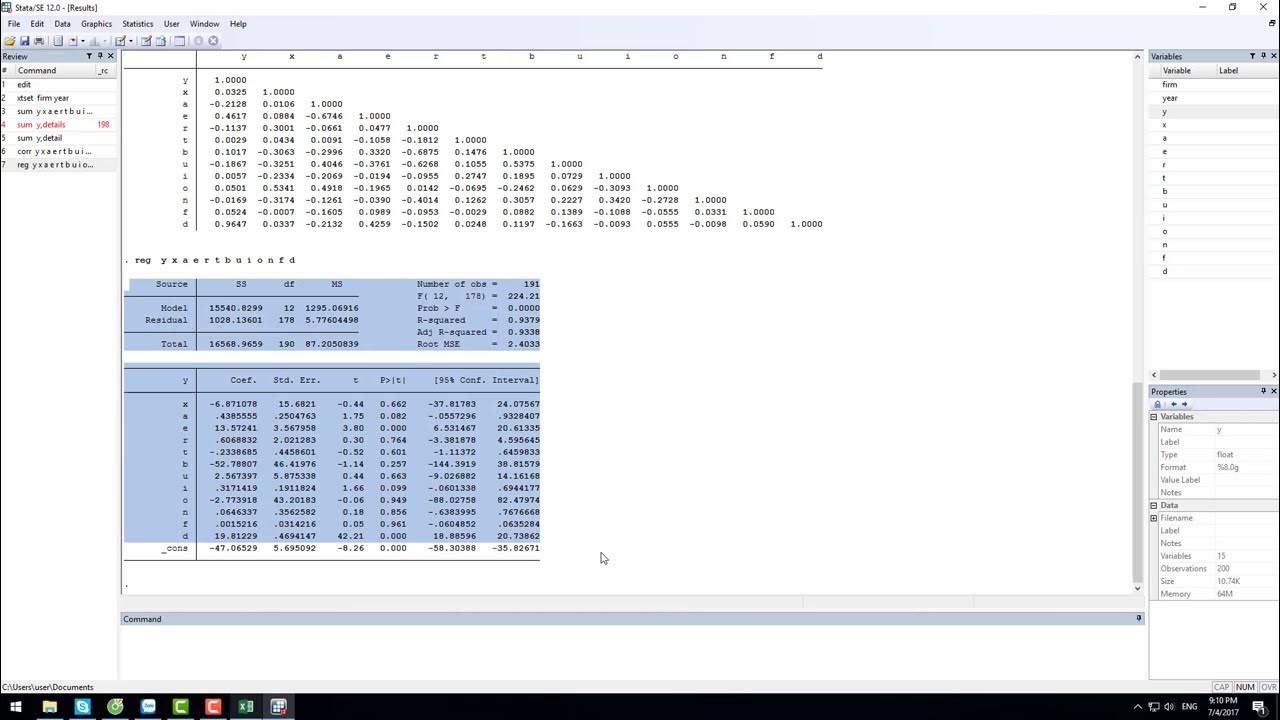
۱۱. رگرسیون خطی با دستور regress
پایه اصلی اکثر تحلیلها، مدل رگرسیون است. در استاتا با تایپ reg y x1 x2 میتوانید رابطه بین متغیرها را بسنجید.
همیشه به مقدار R-squared و سطح معناداری (P-value) توجه کنید. در تحلیل آماری پایان نامه دکتری به Stata، گزارش دقیق ضرایب بتا و فواصل اطمینان الزامی است.
۱۲. استفاده از متغیرهای مجازی (Factor Variables)
نیازی نیست برای هر طبقه از یک متغیر کیفی، دستی متغیر مجازی (Dummy) بسازید. با گذاشتن پیشوند .i قبل از نام متغیر (مثلاً i.education)، استاتا خودش آنها را وارد مدل میکند.
این ویژگی نه تنها کار شما را سریعتر میکند، بلکه احتمال خطا در ساخت متغیرهای مجازی متعدد را در تحلیل داده های رساله دکتری با استاتا به صفر میرساند.
۱۳. کنترل واریانس ناهمسانی با robust
فرضیه همسانی واریانس اغلب در دادههای واقعی نقض میشود. برای رفع این مشکل، همیشه در انتهای دستور رگرسیون خود گزینه vce(robust) را اضافه کنید.
این کار باعث میشود خطاهای استاندارد شما اصلاح شده و نتایج آزمونهای فرض (تست t) قابل اعتمادتر شوند، که یک استاندارد طلایی در مقالات علمی است.
۱۴. آزمون هاسمن (Hausman Test)
در مدلهای پانل، برای انتخاب بین اثرات ثابت (FE) و اثرات تصافی (RE)، باید از آزمون هاسمن استفاده کنید. ابتدا هر دو مدل را تخمین زده و ذخیره کنید، سپس دستور hausman را اجرا کنید.
اگر نتیجه آزمون معنادار باشد (P < 0.05)، مدل اثرات ثابت ترجیح داده میشود. این تصمیمگیری علمی، بخش کلیدی در تحلیل آماری پایان نامه دکتری به Stata است.
۱۵. استفاده از outreg2 برای استخراج جداول
کپی کردن دستی نتایج از استاتا به ورد نه تنها وقتگیر است، بلکه احتمال خطای تایپی بالایی دارد. افزونه outreg2 نتایج شما را مستقیماً به صورت جداول استاندارد ژورنالی در فایل Word یا Excel ذخیره میکند.
یادگیری نصب افزونهها (مانند ssc install outreg2) بخشی از آموزش استاتا است که حرفهای بودن کار شما را نشان میدهد.
۱۶. بررسی همخطی با شاخص VIF
همخطی شدید بین متغیرهای مستقل میتواند ضرایب رگرسیون را غیرقابل اعتماد کند. پس از اجرای رگرسیون، با دستور vif این موضوع را چک کنید.
اگر مقادیر VIF بالاتر از ۱۰ (یا در برخی رشتهها ۵) باشد، باید به فکر حذف برخی متغیرها یا ترکیب آنها باشید تا اعتبار تحلیل داده های رساله دکتری با استاتا حفظ شود.
۱۷. کار با ماکروها (Locals and Globals)
برای خودکارسازی کدها، از ماکروها استفاده کنید. مثلاً میتوانید لیستی از متغیرهای کنترلی را در یک local ذخیره کنید و در تمام رگرسیونها فقط نام آن ماکرو را فراخوانی کنید.
این کار باعث میشود Do-file شما بسیار تمیز و قابل مدیریت باشد، به خصوص زمانی که میخواهید یک متغیر را در ۲۰ مدل مختلف به صورت همزمان تغییر دهید.
۱۸. رسم نمودار رگرسیون با lfit
برای نمایش بصری رابطه بین دو متغیر، ترکیب نمودار پراکنش (scatter) و خط برازش (lfit) بسیار گویاست. دستور twoway (scatter y x) (lfit y x) این کار را انجام میدهد.
نمودارها در جلسات دفاع رساله دکتری بسیار تاثیرگذار هستند و درک بصری بهتری از فرضیات تحقیق به داوران میدهند.
۱۹. تخمین اثرات نهایی با margins
ضرایب رگرسیون (به ویژه در مدلهای غیرخطی مثل Logit) همیشه به راحتی تفسیر نمیشوند. دستور margins اثرات نهایی (Marginal Effects) را محاسبه میکند که به شما میگوید با یک واحد تغییر در X، احتمال وقوع Y چقدر تغییر میکند.
استفاده از marginsplot پس از این دستور، این تغییرات را به صورت گرافیکی نمایش میدهد که برای تحلیل آماری پایان نامه دکتری به Stata بسیار ارزشمند است.
۲۰. رگرسیون لوجستیک برای متغیرهای دوگزینهای
اگر متغیر وابسته شما دو حالتی است (مثلاً موفقیت/شکست)، نباید از OLS استفاده کنید. در این حالت دستور logit یا probit ابزارهای اصلی شما هستند.
در تحلیل خروجی لوجیت، دقت کنید که گزارش Odds Ratio با استفاده از گزینه or معمولاً برای تفسیر نتایج در رسالهها مرسومتر است.
۲۱. استفاده از foreach برای حلقهها
اگر نیاز دارید یک عملیات (مثلاً رسم نمودار یا تست نرمال بودن) را برای ۵۰ متغیر تکرار کنید، از حلقه foreach استفاده کنید. این کار ساعتها در وقت شما صرفهجویی میکند.
تسلط بر حلقهها، مرز بین یک کاربر مبتدی و یک متخصص در آموزش استاتا است و دقت کار را در حجم بالای دادهها تضمین میکند.
۲۲. ذخیره نتایج با eststo و esttab
برای مقایسه چندین مدل رگرسیونی در کنار هم (مثلاً وقتی متغیرهای کنترلی را مرحله به مرحله اضافه میکنید)، از دستورات پکیج estout استفاده کنید.
این کار به شما اجازه میدهد جدولی مشابه مقالات معتبر بسازید که در آن ستونهای مختلف، مدلهای مختلف رساله شما را نمایش میدهند.
۲۳. بررسی نرمال بودن باقیماندهها
پس از رگرسیون، با دستور predict res, residual باقیماندهها را ذخیره کنید و سپس با kdensity یا آزمون swilk وضعیت نرمال بودن آنها را بررسی کنید.
اگر فرضیه نرمال بودن نقض شود، ممکن است نیاز به استفاده از لگاریتم متغیرها یا روشهای ناپارامتریک در تحلیل داده های رساله دکتری با استاتا داشته باشید.
۲۴. استفاده از دستور keep و drop با احتیاط
برای خلوت کردن فایل دادهها، متغیرها یا مشاهدات اضافی را حذف کنید. اما همیشه این کار را در Do-file انجام دهید تا دادههای اصلی شما (Raw Data) دستنخورده باقی بماند.
هرگز دادهای را به صورت دستی در محیط Data Editor حذف نکنید، زیرا در صورت اشتباه، راهی برای بازگشت و اثبات مسیر تحلیل در رساله نخواهید داشت.
۲۵. تحلیل واریانس (ANOVA)
برای مقایسه میانگین در بیش از دو گروه، دستور oneway یا anova به کار میرود. این آزمون برای متغیرهای مستقل طبقهای بسیار کاربردی است.
پس از انوا، حتماً آزمونهای تعقیبی (Post-hoc) مانند bonferroni را اجرا کنید تا مشخص شود دقیقاً کدام گروهها با هم تفاوت معنادار دارند.
۲۶. استفاده از by برای تحلیل زیرگروهها
اگر میخواهید یک تحلیل را به تفکیک جنسیت یا منطقه انجام دهید، از پیشوند bysort category: استفاده کنید. مثلاً bysort gender: sum income.
این دستور یکی از پرکاربردترین ابزارها در تحلیل آماری پایان نامه دکتری به Stata برای مقایسههای بینگروهی سریع است.
۲۷. متغیرهای ابزاری (IV) برای رفع درونزایی
اگر متغیر مستقل شما با جزء خطا همبستگی دارد، دچار درونزایی هستید. در این صورت باید از دستور ivregress 2sls استفاده کنید.
شناسایی و رفع درونزایی یکی از پیچیدهترین بخشهای تحلیل داده های رساله دکتری با استاتا در رشتههای اقتصاد و مالی است که اعتبار علمی کار شما را دوچندان میکند.
۲۸. استفاده از Help خودِ استاتا
هر زمان در مورد دستوری شک داشتید، کافیست تایپ کنید help [command name]. راهنمای استاتا یکی از کاملترین مستندات نرمافزاری جهان است که شامل مثالهای کاربردی نیز میشود.
در مسیر آموزش استاتا، یادگیری نحوه خواندن فایلهای Help مهمتر از حفظ کردن خودِ دستورات است.
۲۹. تنظیم حافظه در نسخههای قدیمی
در نسخههای قدیمی استاتا (قبل از ۱۲)، باید میزان حافظه اشغالی را با set memory تعیین میکردید. در نسخههای جدید این کار خودکار است، اما اگر با دادههای بسیار عظیم (Big Data) کار میکنید، ممکن است نیاز به تنظیم maxvar داشته باشید.
مدیریت بهینه حافظه باعث میشود که سیستم شما هنگام پردازشهای سنگین رساله، دچار هنگ یا کندی نشود.
۳۰. مستندسازی با log
با دستور log using filename تمام دستورات و خروجیهایی که در پنجره Results ظاهر میشوند را در یک فایل متنی ذخیره کنید.
داشتن فایل Log برای هر جلسه تحلیل، یک بیمهنامه برای پژوهش شماست تا در صورت نیاز به بازنگری، دقیقاً بدانید در فلان تاریخ چه نتایجی به دست آورده بودید